12 Invariants, Testing, and Abstraction Barriers
12.1 Invariants of Data Structures
Here’s an interface for a sorted list of numbers.
#lang class/1 ;; An ISorted implements ;; insert : Number -> Sorted ;; contains? : Number -> Boolean ;; ->list : -> [Listof Number] ;; empty? : -> Boolean ;; Invariant: The list is sorted in ascending order. ;; Precondition: the list must not be empty ;; max : -> Number ;; min : -> Number
How would we implement this interface?
#lang class/1 ;; A Sorted is one of ;; - (new smt%) ;; - (new scons% Number Sorted) (define-class smt% (check-expect ((new smt%) . contains? 5) false) (define (contains? n) false)) (define-class scons% (fields first rest) (check-expect ((new scons% 5 (new smt%)) . contains? 5) true) (check-expect ((new scons% 5 (new smt%)) . contains? 7) false) (check-expect ((new scons% 5 (new scons% 7 (new smt%))) . contains? 3) false) (check-expect ((new scons% 5 (new scons% 7 (new smt%))) . contains? 9) false) (define (contains? n) (or (= n (field first)) ((field rest) . contains? n))))
However, we can write a new implementation that uses our invariant to avoid checking the rest of the list when it isn’t necessary.
(define (contains? n) (cond [(= n (field first)) true] [(< n (field first)) false] [else ((field rest) . contains? n)]))
Because the list is always sorted in ascending order, if n is less than the first element, it must be less than every other element, and therefore can’t possibly be equal to any element in the list.
Now we can implement the remaining methods from the interface. First, insert
smt%
(check-expect ((new smt%) . insert 5) (new scons% 5 (new smt%))) (define (insert n) (new scons% n (new smt%)))
scons%
(check-expect ((new scons% 5 (new smt%)) . insert 7) (new scons% 5 (new scons% 7 (new smt%)))) (check-expect ((new scons% 7 (new smt%)) . insert 5) (new scons% 5 (new scons% 7 (new smt%)))) (define (insert n) (cond [(< n (field first)) (new scons% n this)] [else (new scons% (field first) ((field rest) . insert n))]))
Note that we don’t have to look at the whole list to insert the elements. This is again a benefit of programming using the invariant that we have a sorted list.
Next, the max method. We don’t have to do anything for the empty list, because we have a precondition that we can only call max when the list is non-empty.
scons%
(define real-max max) (check-expect ((new scons% 5 (new smt%)) . max) 5) (check-expect ((new scons% 5 (new scons% 7 (new smt%))) . max) 7) (define (max) (cond [((field rest) . empty?) (field first)] [else ((field rest) . max)]))
Again, this implementation relies on our data structure invariant. To make this work, though, we need to implement empty?.
smt%
(check-expect ((new smt%) . empty?) true) (define (empty?) true)
scons%
(check-expect ((new scons% 1 (new smt%)) . empty?) false) (define (empty?) false)
scons%
(define (min) (field first)) (define (->list) (cons (field first) ((field rest) . ->list)))
12.2 Properties of Programs and Randomized Testing
A property is a claim about the behavior of a program. Unit tests check particular, very specific properties, but often there are more general properties that we can state and check about programs.
Here’s a property about our sorted list library, which we would like to be true:
∀ sls : ISorted . ∀ n : Number . ((sls . insert n) . contains? n)
How would we check this? We can check a few instances with unit tests, but this property makes a very strong claim. If we were working in ACL2, as in the Logic and Computation class, we could provide a machine-checked proof of the property, verifying that it is true for every single Sorted and Number.
For something in between these two extremes, we can use randomized testing. This allows us to gain confidence that our property is true, with just a bit of programming effort.
First, we want to write a program that asks the question associated with this property.
;; Property: forall sorted lists and numbers, this predicate holds ;; insert-contains? : ISorted Number -> Boolean (define (insert-contains? sls n) ((sls . insert n) . contains? n))
Now we make lots of randomly generated tests, and see if the predicate holds. First, let’s build a random sorted list generator.
;; build-sorted : Nat (Nat -> Number) -> Sorted (define (build-sorted i f) (cond [(zero? i) (new smt%)] [else (new scons% (f i) (build-sorted (sub1 i) f))])) (build-sorted 5 (lambda (x) x))
Oh no! We broke the invariant. The scons% constructor allows you to break the invariant, and now all of our methods don’t work. Fortunately, we can implement a fixed version that uses the insert method to maintain the sorted list invariant:
;; build-sorted : Nat (Nat -> Number) -> Sorted (define (build-sorted i f) (cond [(zero? i) (new smt%)] [else ((build-sorted (sub1 i) f) . insert (f i))])) (check-expect (build-sorted 3 (lambda (x) x)) (new scons% 1 (new scons% 2 (new scons% 3 (new smt%)))))
Now build-sorted produces the correct answer, which we can easily verify at the Interactions window.
Using build-sorted, we can develop random-sorted, which generates a sorted list of random numbers.:
;; Nat -> Sorted (define (random-sorted i) (build-sorted i (lambda (_) (random 100))))
Given these building blocks, we can write a test that checks our property.
(check-expect (insert-contains? (random-sorted 30) (random 50)) true)
Every time we hit the Run button, we generate a random sorted list of numbers, and check if a particular random integer behaves appropriately when inserted into it. But if we could repeatedly check this property hundreds or thousands of times, it would be even more unlikely that our program violates the property. After all, we could have just gotten lucky.
;; Nat (Any -> Any) -> 'done ;; run the function f i times (define (do i f) (cond [(zero? i) 'done] [else (f (do (sub1 i) f))]))
(do 1000 (lambda (_) (check-expect (insert-contains? (random-sorted 30) (random 50)) true)))
When this says that we’ve passed 1000 tests, we’ll be more sure that we’ve gotten our function right.
;; Property: forall sorted lists and numbers, this predicate holds ;; insert-contains? : ISorted Number -> Boolean (define (insert-contains? sls n) (sls . contains? n))
Now we get lots of test failures, but the problem is not in our
implementation of sorted lists, it’s in our property definition. If
we had instead had a bug in our implementation, we would have
similarly seen many failures. Thus, it isn’t always possible to tell
from a test failure, or even many failures, whether it’s the code or
the specification is wrong—
This is why it’s extremely important to get your specifications (like contracts, data definitions, and interface definitions) correct. Your program can only be correct if they are.
12.3 Abstraction Barriers and Modules
Recall that in our original version of build-sorted, we saw that the
scons% constructor allowed us to violate the invariant—
To address this, we set up an abstraction barrier, preventing other people from seeing the scons% constructor. To create these barriers, we use a module system. We will consider our implementation of sorted lists to be one module, and we can add a simple specification to allow other modules to see parts of the implementation (but not all of it).
Modules in our languages are very simple—
Here’s the module implementing our sorted list, which we save in a file called "sorted-list.rkt".
sorted-list.rkt
#lang class/1 ;; ... all of the rest of the code ... (define smt (new smt%)) (provide smt)
We’ve added two new pieces to this file. First, we define smt to be an instance of the empty sorted list. Then, we use provide to make smt, but not any other definition from our module, available to other modules.
Therefore, the only part of our code that the rest of the world can see is the smt value. To add new elements, the rest of the world has to use the insert method.
#lang class/1 (require "sorted-list.rkt") (smt . insert 4)
Here, we’ve used require, which we’ve used to refer to libraries that come with DrRacket. However, we can specify the name of a file, and we get everything that the module in that file provides, which here is just the smt definition. Everything else, such as the dangerous scons% constructor, is hidden, and our implementation of sorted lists can rely on its invariant.
12.4 Exercises
12.4.1 Quick Lists
Van Horn has always been underwhelmed by the fact that list-ref is such a slow operation when you’re accessing elements deep down in a big list. Why should it take a million rests just to get the millionth element?
To combat this drawback of an otherwise lovely data structure, the list, Van Horn has devised an idea for a new implementation of lists that would let you get the millionth element in about 20 operations. If his idea works, the list-ref operation will take roughly log(i) steps to get the ith element. The other list operations, on the other hand, would remain more or less just as efficient as before; taking the rest of a list, for example, might take a few more steps to compute, but it would be some small constant number of extra steps. In the end, we’d have something that behaves just like a list, but with a much better list-ref operation.
Your task is to take Van Horn’s idea and implement it. Since you’ll be building a new kind of list data structure, let’s first agree on the list interface we want:
;; A [List X] implements ;; - cons : X -> [List X] ;; Cons given element on to this list ;; - first : -> X ;; Get the first element of this list ;; (only defined on non-empty lists) ;; - rest : -> [List X] ;; Get the rest of this ;; (only defined on non-empty lists) ;; - list-ref : Natural -> X ;; Get the ith element of this list ;; (only defined for lists of i+1 or more elements) ;; - length : -> Natural ;; Compute the number of elements in this list ;; empty is a [List X] for any X.
In other words, you have to make an object named empty that implements the list interface above. Lists should work just like we’re used to, so for example, these tests should all pass if empty is appropriately defined:
#lang class/1 (require "your-implementation-of-lists.rkt") ; provides empty (define ls (empty . cons 'a . cons 'b . cons 'c . cons 'd . cons 'e)) (check-expect (empty . length) 0) (check-expect (ls . length) 5) (check-expect (ls . first) 'e) (check-expect (ls . rest . first) 'd) (check-expect (ls . rest . rest . first) 'c) (check-expect (ls . rest . rest . rest . first) 'b) (check-expect (ls . rest . rest . rest . rest . first) 'a) (check-expect (ls . list-ref 0) 'e) (check-expect (ls . list-ref 1) 'd) (check-expect (ls . list-ref 2) 'c) (check-expect (ls . list-ref 3) 'b) (check-expect (ls . list-ref 4) 'a)
So now let’s talk about Van Horn’s idea.
Van Horn thinks if instead of representing a list as a “list of
elements” you could do better by representing a list as a “forest of
trees of elements”. (A forest is just an arbitrarily long
sequence of trees.) Moreover, the trees will get bigger and bigger as
you go deeper into the forest, and every tree is full. (A
full tree is a binary in which every node has a left and
right subtree that are full and of the same.) For the moment, don’t
worry about why this makes list-ref fast—
So here are the key invariants of a quick list:
A quick list is a forest of increasingly large full binary trees.
With the possible exception of the first two trees, every successive tree is strictly larger.
Now that we have the invariant, let’s talk about the operations and how they both can use and maintain the invariant.
First, first. Since the list must be non-empty, we know the forest has at least one tree, so we can get the first element of the list by getting “the first” element of the tree, which for quick lists, will be the top element.
Now, length. If the forest is empty, the list has length 0. If a forest has a tree, the length of the list is the size of the tree plus the size of the rest of the forest. (It’s useful to store the size of a tree separately from a tree so that you don’t have to compute it every time you need it.)
The list-ref method works as follows: if the index is 0, the list must be non-empty, so take the first element, i.e. the top element of the first tree in the forest. If the index is non-zero, there are two case: if it’s less than the size of the first tree, the element is in that tree, so fetch it from the first tree. If it’s larger, adjust the index, and look in the remaining trees of the forest.
To fetch an element from a tree: if the index is zero, the element is the top element. Otherwise, if the index is less than half the size, it’s on the left side; if the index is greater than half, it’s on the right. (You might do yourself a favor a develop tree-ref for full binary trees and get it working and thoroughly tested before attempting list-ref.)
These element-producing operations considered so far have used the invariant. Now let’s turn to the list-producing operations which must maintain it.
When an element is consed, there are two cases to consider:
If there at least two trees in the forest and the first two trees are the same size, then make a new tree out of these two and with the given element on top. Here it is pictorially; we are given a forest of full binary trees where the first two trees have the same height:

To cons on the new element, we make a node that contains the element and the first two trees as its left and right subtree:
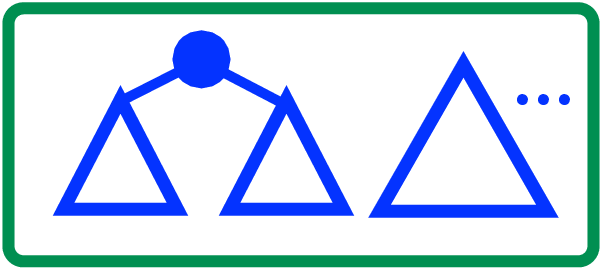
Notice how this first tree is necessarily full, since the first two trees were full and the same height; notice how this new first tree in the forest is at most as large as the second tree (previously the third tree). These two observations demonstrate that the invariant holds on the resulting forest, so cons really makes a quick list in this case.
Otherwise, we know that the size of the trees in the forest is strictly increasing:
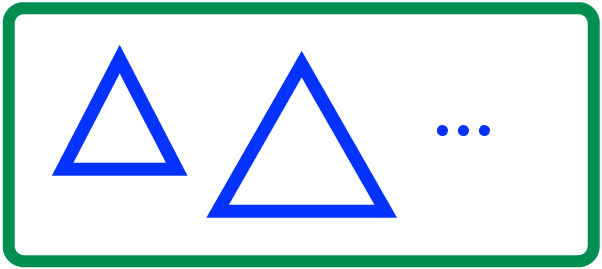
Therefore, we can just make a new tree with one element and make it the first tree in the forest:
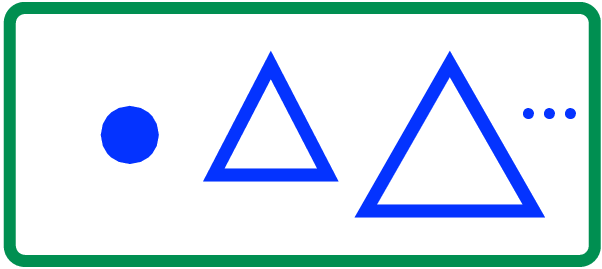
Notice how the one element tree is obviously full and that it is no larger than the (now) second tree in the forest, so the invariant holds in this case too.
To take the rest of a list, there must be at least one tree in the forest (since the list is non-empty):
We want to split this tree into its left and right and make these the first two trees in the forest. The element that was on top is dropped on the floor and we’re left with a representation of the rest of the list:
And that’s that. When writing your code you want to make sure the invariants are always true. Good code should make this fact obvious; bad code, not so much.
This is a nice little exercise in data structure design and implementation, and although Van Horn wishes this were really his idea, he actually got it from reading a book by Chris Okasaki, who has designed a bunch of these kinds of data structures. Go forth, and may your list-ref never be slow again.