Lecture 18: Generic trees and other data structures
Generic trees based on composite patterns.
Higher-order functions on composites.
Binary search trees.
Tree-like data structures in Java.
Other relevant data structures in Java.
18.1 A general hierarchy
In Lecture 17: Hierarchical structures we used the composite design pattern to represent an organizational hierarchy. Most of the operations that we designed for the organizational hierarchy (counting, serializing) are related to (and leverage) the structure of the hierarchy, and not the employee data. This hints at the possibility that we can generalize a composite hierarchy and its operations so that they can be used with any data.
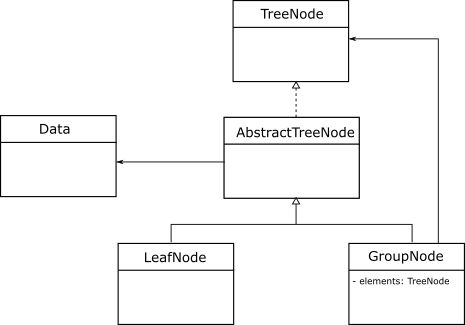
To review, the general structure of the composite design pattern is as follows:

The design of the composite pattern above identifies two types of nodes: leaves and groups (composites). While mapping this structure to our organization hierarchy, we observe that each node contains employee data (name, gender, pay and possibly date of termination). We can explicitly separate the employee data from the hierarchical structure by embedding the former inside the latter as a "data object".
We can create an employee hierarchy using this design as follows:

18.2 Generic tree operations
18.2.1 Constructing the hierarchy
We can generalize the concept of the addSupervisee method from Lecture 17 by noting that it had two arguments: the node to be added (Employee) and identifying information about an existing node (the name of the supervisor). We can generalize this to “the node to be added” and “something that identifies its parent”:
public interface TreeNode<T> { /** * Add the given node as a child to a node in this tree * identified by the predicate. If no node is identified by the predicate the tree * remains unchanged. * @param identifier a predicate that is used to * identify the node. * @param child the node that must be added as a child * @return the resulting hierarchy starting at this node */ TreeNode<T> addChild(Predicate<T> identifier, TreeNode<T> child); }
The predicate provides a test that will pass only for the node to which the child must be added. We generalize its implementation as follows:
//In GroupNode @Override public TreeNode<T> addChild(Predicate<T> identifier, TreeNode<T> child) { if (identifier.test(this.data)) { this.children.add(child); //add it here and return return this; } for (int i=0;i<this.children.size();i++) { //add to child and mutate the child this.children.set( i, this.children.get(i).addChild(identifier,child)); } return this; } //In LeafNode: @Override public TreeNode<T> addChild(Predicate<T> identifier, TreeNode<T> child) { if (identifier.test(data)) { //promote this to a group tree node GroupNode<T> newNode = new GroupNode<T>(this.data); newNode.addChild(identifier,child); return newNode; } return this; }
Using this method, we can re-implement the OrganizationImpl implementation without changing the Organization interface as follows:
public class OrganizationImpl implements Organization { private TreeNode<Employee> root; public OrganizationImpl(String nameCEO, double pay, Gender gender) { root = new LeafNode<>(new InternalEmployee(nameCEO,pay,gender)); } @Override public void addEmployee(String name, double pay, Gender gender, String supervisorName) { Employee newEmployee = new InternalEmployee(name,pay,gender); TreeNode<Employee> newNode = new LeafNode<>(newEmployee); root = root.addChild(e->e.getName().equals(supervisorName),newNode); } @Override public void addContractEmployee(String name,double pay,Gender gender, int endDate,int endMonth,int endYear, String supervisorName) { Employee newEmployee = new ContractEmployee(name,pay,gender,endDate, endMonth,endYear); TreeNode<Employee> newNode = new LeafNode<>(newEmployee); root = root.addChild(e->e.getName().equals(supervisorName),newNode); } }
Specifically the client (the OrganizationImpl class) ensures that the appropriate data is inserted into the appropriate type of node, depending on the context (e.g. only an internal employee can be inserted in a group node).
We note that because neither the Organization interface nor the name of its implementation changed, all tests from Lecture 17: Hierarchical structures can be used directly!
18.2.2 Serializing the tree
Converting a tree into a list is a worthwhile generic operation. We can generalize it from toList above as follows:
public interface TreeNode<T> { ... /** * Convert the tree into a list. * @return the resulting list */ List<T> toList(); }
Its implementation remains largely unchanged from the implementation for the Employee classes.
//In LeafNode: @Override public List<T> toList() { List<T> result = new ArrayList<T>(); result.add(this.data); return result; } //In GroupNode: @Override public List<T> toList() { List<T> result = new ArrayList<T>(); result.add(this.data); for (TreeNode<T> child: children) { result.addAll(child.toList()); } return result; }
18.2.3 Higher-order functions: map
The map was motivated as a function that converts a list of one type into an equivalent list of another type by applying a function to convert each data element from the first to the second. However this operation is not restricted to lists: it applies to most recursive unions, including trees.
As we are designing a generic tree, we can generalize the map operation on it as well: it is a function that can convert a tree with data of type T into a tree of the same structure with data of type R. It requires a function that transforms a T object to a R object.
public interface TreeNode<T> { ... /** * A map higher-order function on this tree. Produces a tree with identical * structure but whose data is of the specified return type * @param transform the function that maps from the * data in this tree to the data in the resulting tree * @param <R> the type of the resulting data * @return the root of the corresponding mapped tree */ <R> TreeNode<R> map(Function<T,R> transform); }
The Function<T,R> interface encapsulates a lambda function that takes a single argument of type T and returns a value of type R.
How do we implement a map? The map must construct a tree of identical structure, i.e. "replicate" a tree. We frame it as follows: We replicate a tree with root X by creating a new composite node S with the same data as X and add to it the replicated forms of the children of X. If the tree has a single node, we replicate it directly. As before, this leads to a straightforward depth-first traversal of the tree.
To implement the map, we insert transform(data) into the new tree node instead of data directly.
//In LeafNode: @Override public <R> TreeNode<R> map(Function<T,R> transform) { return new LeafNode<R>(transform.apply(this.data)); } //In GroupNode: @Override public <R> TreeNode<R> map(Function<T,R> transform) { GroupNode<R> newNode = new GroupNode<R>(transform.apply(this.data)); for (TreeNode<T> child:children) { newNode.children.add(child.map(transform)); } return newNode; }
18.2.4 Higher-order functions: fold/reduce
The fold/reduce operation was motivated as being of the form List => value, but it can be generalized to most recursive unions, including trees. Thus we can write a generic reduce operation of the form Tree => value.
Recall that a reduce operation takes two arguments: an initial value and a combiner function that combines two values of the return type. We use the BiFunction<T,R,S> interface to specify the combiner.
public interface TreeNode<T> { ... /** * A reduce higher-order function on this tree. Produces a single value of * type T * @param initialValue the initial value of the accumulator of the reduce * @param combiner a function that takes two values of type T and combines * them into a single value of type T * @return the result of the reduce, as an object of type T */ T reduce(T initialValue, BiFunction<T,T,T> combiner); }
How do we implement a reduce operation? A reduction of a tree with root R is the result of combining the reduction of all its children with the data at R. If the tree has a single node, its reduction is simply the data at that node.
//In LeafNode: @Override public T reduce(T initialValue, BiFunction<T, T,T> combiner) { return combiner.apply(initialValue,this.data); } //In GroupNode: @Override public T reduce(T initialValue, BiFunction<T,T,T> combiner) { T result = this.data; for (TreeNode<T> child:children) { result = child.reduce(result,combiner); } //at this point result is the combination of this.data and reductions of its children return combiner.apply(initialValue,result); //combine result and initialValue and return }
18.2.5 Application of map and reduce
We now explore several applications of the map and reduce operations to our implementation of the organization hierarchy.
18.2.5.1 Total size, size by gender
The size of an organization is the same as the number of nodes in the tree. We visualize the counting in an unorthodox way: we substitute a "1" for each node in the tree and then add all of them. This can be expressed as a map (Tree<Employee> => Tree<Number>) followed by a reduce (Tree<Number> => Number):
Map the tree into a tree of numbers, such that there is a 1 for each node.
Reduce the tree of numbers by using an initial value of 0 and the combiner as the addition operation.
Counting the number of employees of a specific gender amounts to determining the number of nodes in the tree that fulfill a given condition. It can be implemented similar to the above, but modifying the first step.
Map the tree into a tree of numbers, such that there is a 1 for each node that contains an employee of the specific gender, 0 for all other nodes.
Reduce the tree of numbers by using an initial value of 0 and the combiner as the addition operation.
//In OrganizationImpl public class OrganizationImpl implements Organization { private TreeNode<Employee> root; ... @Override public int getSize() { return root.map(e->new Integer(1)).reduce(0,(a,b)->a+b); } @Override public int getSizeByGender(Gender gender) { return root.map( e-> { if (e.getGender()==gender) { //condition to be counted return new Integer(1); } else { return new Integer(0); } }).reduce(0,(a,b)->a+b); } }
Do Now!
Implement the countPayAbove and terminatedBefore operations similarly.
18.2.5.2 List of all employee names
The allEmployees method can be thought of as first converting the organization hierarchy into a hierarchy of employee names, and then converting it to a list. Thus this operation can be expressed as a map (Tree<Employee> => Tree<String>) followed by a Tree<String> => List<String>:
//In OrganizationImpl public class OrganizationImpl implements Organization { private TreeNode<Employee> root; ... @Override public List<String> allEmployees() { return root.map(e->e.getName()).toList(); } }
18.3 Hierarchical data structures: Binary search tree
The above examples show how to represent data in a hierarchy. However a hierarchical structure can be used not only to represent data accurately but also organize it efficiently. A good example of this is the binary search tree.
A binary search tree is a data structure to store data that is ordered (given two pieces of data, we can determine whether one is lesser than, equal to or greater than the other). This tree puts two constraints on how data can be organized in it:
A node in the tree can have up to 2 children (hence the name "binary"). They are referred to as "left" and "right".
The data stored at a node is greater than all the data contained in its left subtree, and is lesser than all the data contained in its right subtree.
The second condition is responsible for the resulting efficient organization.
18.3.1 Data representation
We note that a binary search tree has two types of nodes: nodes with children and nodes without children. One option is to design it like the organization hierarchy: all nodes have data, but only group nodes have children. A variation of this design is as follows:

In this design only the ElementNode has data and up to two children. The EmptyNode acts as a sentinel. Every path from the root of the tree ends with an empty node. In this sense this design matches that of our lists (see Lecture 7). This variation fits the binary search tree better for the following reasons:
It allows a proper representation for an empty tree.
Traditional implementations of binary search trees using null as an indication that the "tree has ended". null is a purely programming construct that simply signals "the absence of an object". From the perspective of data representation, the end of a path is not the same thing as there’s nothing there, so we must be at the end. Practically using null produces several programming problems. For example one must explicitly check for nullness before attempting an operation.
Since the binary search tree has a constraint on where nodes can be added, we cannot explicitly specify the children or parent of a newly added node (unlike how we specified a supervisee for a supervisor explicitly). Therefore we are free from the constraint of “always having a node present in the tree”. This is in contrast with our organization hierarchy, where having one employee in the tree was necessary to act as a supervisor for adding another employee.
18.3.2 Binary search tree operations
The binary search tree is typically used for dictionary-type operations, and thus is termed to be an implementation of the Dictionary Abstract Data Type (ADT). The typical operations in this ADT are:
Add an element to the dictionary.
Determine if an element is in the dictionary.
Remove an element from the dictionary.
Return the elements in the dictionary in order.
Return the element at a given position in order.
Exercise
Convert the above ADT into an interface, and implement it with the given design. We assume that you are familiar with how binary search trees work, so consider this largely as a design task, rather than an algorithmic task.
18.4 Data Structures in Java
The Dictionary ADT above is an example of a data structure that orders elements in it, efficiently searches for data and offers queries related to order. Being able to efficiently add, remove and search data with or without order are useful operations. Java (and many other languages) have several implementations of such data structures. It is good to be aware of these implementations, as they provide out-of-the-box, robust and time-tested solutions.
18.4.1 List, sets and maps
Organization of data in general can be categorized into three groups.
18.4.1.1 Lists
A list is a linear sequence of data. Elements in a list have the notion of order, or position. The List<T> encapsulates all list-type operations. There are several implementations of this interface. The LinkedList implements a list as a linked list, similar to our implementations in Lecture 4 and Lecture 5. The ArrayList implements this interface using a contiguous representation like arrays. While both offer the same methods (from the List<T> interface), the internal organization affects the efficiency of these operations. For example, accessing a specific position in the list (using the get method) is much more efficient with an array list, due to the array’s random access property.
18.4.1.2 Sets
A set embraces the mathematical notion of a set. Elements can be inserted and removed from a set, but a set does not store duplicates. The Set<T> interface represents a set in Java. A set generally has no notion of order, but Java provides a more specific "ordered" set that behaves like a set, but offers more operations based on order. The SortedSet<T> interface represents an ordered set. While sets answer exact search queries (is element X present?), a navigable set answers range queries (give me the next highest element than X in the set). The NavigableSet interface represents a navigable set.
The TreeSet class represents a sorted, navigable set. As its name suggests it uses a binary search tree for its implementation (read more about it in its documentation). As a tree set is an ordered set, it needs a way to infer order between two elements. It works with Comparable and Comparator objects. Which of these interfaces is used depends primarily on the nature of the data being stored (please revisit the general sorting discussion from lists).
The HashSet class implements a unordered set. This means that it offers all Set operations but does not guarantee any ordering of elements in it. As it name suggests, it uses a hash table as its underlying data structure. Hash tables rely on a hash function that converts the data to be added into a number that can be used as an index into an underlying list (usually an array). This hash function is the hashCode method which is present in every Java class. When an element is to be added to/searched in a hash table, its hashCode method is used. Hence this method should be properly implemented for best performance. Although the underlying math for a good hash function can be complicated, Java provides several inbuilt hash functions to facilitate this (look at Integer.hashCode(...), Long.hashCode(...) and the more general Objects.hash(...)). It is important to remember that if you override the equals method for a class, you must override the hashCode method as well for consistency.
18.4.2 Maps
A map is a structure that maps one piece of data (keys) to another piece of data (value). In contrast with lists and sets, a map entry is a pair. This organization is desirable when we have data that can be identified with one of its parts (e.g. an employee record with SSN, a pizza customer with a phone number, etc.). It may be useful to think of a map as a table of two columns (although that is not how it may actually be organized). A map typically allows insertion and deletion (of a key-value pair), searching (for data based on key), and in some cases, order-based queries. Maps have some similarities with sets (there are ordered and unordered maps, maps do not allow duplicate keys, etc.)
The organization of map-related classes and interfaces mimics that of sets. The Map interface represents a map ADT. The SortedMap and NavigableMap interfaces represent an ordered map and a navigable map respectively. The TreeMap class implements an ordered map (the keys are ordered) based on binary search trees, whereas the HashMap class implements an unordered map (the keys are hashed) based on hash tables.