
This article describes both paging and CPU caches as part of a common framework for general caches. In paging, the RAM acts as a cache for the secondary storage, within the memory hierarchy.
The swapfile is a region of disk that contains the memory for each process. Thus, a (pid, address) specifies a unique address in the swapfile, where the memory at that address is located.
A physical address is the actual address in RAM. A virtual address is the address in the swapfile.
The RAM serves as a cache for the swapfile. The CPU cache is a cache for the RAM. And the registers are read or written via the CPU cache. Recall that the registers can be read of written only by load/stor (e.g., lw and sw in the MIPS assembly language).
If we don't find the data in the CPU cache, we call that a cache miss. If we don't find the data in RAM, we should logically call that a "page miss". In fact, it is called a page fault (a "fault" or error in paging the memory of the swapfile into RAM).
For a traditional description of paging, see ostep.org. In particular, see: Chapters 15 ("Address Translation"); Chapters 18 ("Introduction to Paging"); Chapters 19 ("Translation Lookaside Buffer (TLB)"); and Chapters 20 ("Advanced Paging Tables (multi-level page translation tables)");
When searching for the contents at an address, the software can inspect the page translation table to find the correct page frame, and then apply the original page offset of that address. However, this approach requires two accesses to RAM: first to the page translation table; and second to the actual page frame.
Since the RAM access is slow compared to a CPU clock cycle, the cost of accessing RAM twice for a single address is expensive. To ameliorate this situation, the CPU chip typically contains an MMU (Memory Management Unit), and the MMU typically includes a TLB (Translation Lookaside Buffer). The hardware TLB contains a hardware cache for the page translation table. Since the TLB is small, it can only contain the "hot" pages (the pages that are most frequently used.u
So, in the optimal case, the CPU translates its virtual address to a physical address directly, using the TLB. At the same time, the hardware MMU checks the page permissions (PROT_READ, PROT_WRITE, PROT_EXEC). If the entry is not found in the TLB, a TLB fault is registered to the operating system (possibly with hardware assistance), and the missing page entry is copied by the operating system from the RAM to the TLB. See Chapter 19 (Translation Lookaside Buffers) of ostep.org for further details on the TLB.
We have seen that the TLB is a cache for the page translation table. Recall that the page translation table is part of a caching mechanism in which the page frames of the RAM are a cache for the pages of the swapfile. An entry in the page translation table may indicate that for a (virtual) page, there is no corresponding (physical) page frame. In this case, a page fault is registered with the operating system as an exception. The corresponding exception handler in the operating system must then arrange for The page must be paged in from the swapfile to an empty page frame, and the page translation table must be updated.
When there is no more free space in the cache, and a request to store a new cache entry arrives, then an existing cache entry must be evicted. The decision of which cache entry to evict is called the eviction policy. LRU (Least Recently Used) is a common choice for an eviction policy, although other variants are sometimes used. When evicting a cache entry, if the Modified bit is set, then the cache entry must be copied back to the original location, before declaring the cache entry as empty. If the Modified bit is not set, then there a performance optimization allows us to skip writing the cached data back to the original location.
A cache may follow a lazy policy or an eager policy. In a lazy policy, one updates cache entries for which the Modified bit is set, only at the time that we evict the cache entry. In an eager policy, we update cache entries for which the Modified bit is set at an earlier time, when resources are not being used for other purposes.
As described in General Principle #3, the virtual address from the CPU can be split into two fields: data block number; and offset into the data block. This is the end of the story for a fully associative cache. However, in the case of a direct-mapped cache, the "data block number" will be decomposed further, into a tag field and an index field.
An entry in a fully associative cache includes a Modified (Dirty) bit, but it also includes a Valid (Present) bit. If an entry in the cache is not currently being used, then the Valid bit is set to zero. So, when the computer first boots up, the Valid bits of all cache entries are set to zero.
One speaks of a cache hit and a cache miss. The processing of a cache hit or cache miss is carried out entirely in hardware. Recalling "General Principle #3", a virtual address can be split into a data block number, and an offset in the specified data block.
Finally, the largest problem for a fully associative cache is that one requires a comparator in hardware that can compare the data block number of the address from the CPU and the data block number found in a CPU cache entry. Each CPU cache entry requires a separate comparator. In searching the fully associative cache, the hardware invokes the comparator of each cache entry -- all in parallel. If one comparator registers "True" (there is a match), then we have a "cache hit", and the corresponding data block is copied in its entirety to the CPU core that issued the "lw" or "sw". (The data block is copied in its entirety, due to General Principle #2.)
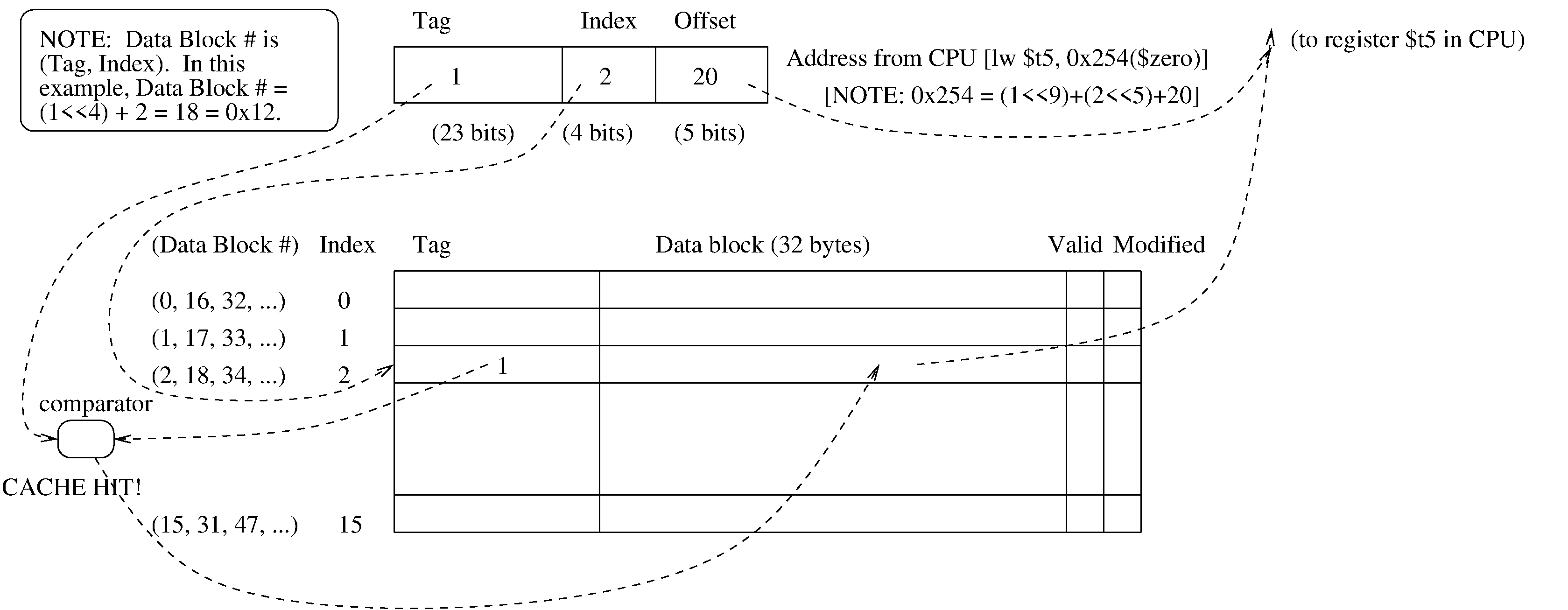
In this example, the CPU has executed:
lw $t5, 0x254($zero).
(Recall that only the "load" and "store" assembly instructions can
access RAM or virtual memory.)
In this example,
In this example, the address from the CPU has an index field with value 2. So, it causes the cache to fetch the tag from cache line number 2. This tag from the cache is compared with the tag in the address from the CPU. Both tags are 1. So, the comparator finds them equal, and declares that this is a cache hit! Because it is a cache hit, the data block from cache line number 2 is copied in its entirety into a buffer in the CPU (actually into a buffer of the CPU core that issued the "lw" instruction). The offset of 20 is then used to extract the word from that buffer.
The advantage of the direct-mapped cache is that it only requires one comparator. A comparator is a logic circuit, and it takes up more "chip real estate" than the RAM that holds the data of the cache.
On the ohter hand, the direct-mapped cache has a serious disadvantage. Suppose the program is copying from one array to another, and the addresses differ by exactly 512 bytes. For example, maybe we are copying from address 596=0x254 (as shown in the diagram) to address 596+512=1108=0x454. The encoding of the destination address is (tag=2, index=2, offset=20).
So, the source address (0x254) and the destination address (0x454) should both be stored at index 2 in this direct-mapped cache. But they have tag 1 and tag 2, respectively. So, the comparator will declare a cache miss as we alternate between the two addresses. And if we are copying a source array to a destination array, we will see a cache miss again at index 2, as we examine the next address of the array (which will have offset=24, assuming an array of int's). And then another cache miss in copying at offset 28, and so on.
The goal of a set associative cache is to fix the problem with direct-mapped caches. Recall that if you copy a "source" array into a "destination" array while using a direct-mapped cache, and if the difference in the base address of the two arrays is exactly a power of two, then you might find that your addresses for the source and destination array decomposed into exactly the same offset and index, and only the tag is different. This is bad, since then we can't save both the source and destination addresses in the same cache entry.
The solution is a 2-way set associative cache. One replaces each cache line (tag + data block) by two cache lines that share the same index. (Maybe we should then call the index a "group index" or "set index".) Now, even though the source and destination arrays may have the same index field, we have two cache lines at that group index. So, we can simultaneously store source array element and destination array element at the same group index.
For details, read any good exposition. A good exposition should explain that the group of two cache lines acts as a fully associative cache with two cache entries. And the set of all cache groups can be thought of as a direct-mapped cache in which each cache entry is replaced by the group of two cache entries.
And as you would expect, one can generalize to an n-way set associative cache for arbitrary ?n. You will sometimes see a 4-way set associative cache, but 2-way set associative caches are the most common, since they suffice to fix the common problem seen when copying a source array into a destination array.