Summary
This week we're working with threads. One step of creating a search engine
is to index all the items we might want to search. This gets around the problem of
having to search through everything each time we query. Here's an example:
If I want to get a list of movies that are a particular genre, if I don't have an
index, the only thing I can do is load up a list of movies and then search through them
(possibly sorting via genre first, then binary search). But, if I've indexed the list of
movies by genre, then I already have that list. Then, searching through that list of
comedies becomes much more efficient.
How does this all fit together?
In the bigger scheme of things, we're putting pieces together to build a search engine.
A search engine has a few components: a file crawler, a file processor, an indexer, and
a query processor. The file crawler starts in one place, and traverses to find other files.
On the web, this means starting at one page and following all the links on the page; in
a file system, it means starting in one directory and traversing through the directory
structure until all files have been foun. The file processor takes each of those files and
finds significant words or concepts in the file. The indexer creates a data structure that
(essentially) populates a data structure that makes it easy to find documents that have
similar topics, or find documents that contain a certain word. The query processor lets
us work with that data structure to get the results based on what we ask for.
In this homework, I'm providing you with a working movie indexer. We have a bunch of movie
data, and you're going to build the pieces together to index the titles of these movies.
Once the movies have been indexed, when we query the index, we will list out all of the
movie titles that contain that word.
The trick is that we have about 5 million movies, videos and TV shows that we want to
index. We can't just load them all into memory and search through them! We have to index
them.
What does it mean to index them? Well, we start with a bunch of files (about 1000),
and each file contains about 10,000 records. We open each file, get the words in the
title of the movie from a row, and save which file and which row that record is in.
Then, we want to find the movie record that has a title with a given word,
we look up that word in our index, which has filename and row number of a movie with that
word, and we open that file, go to that row, and print it out.
So what are you building in this assignment? First, you're going to write the part that does the
file processing. This should be straightforward; you've done this a bunch already.
But, we have so much data to deal with, we're going to throw a few threads at it at a time.
Because your virtualbox is set up to have a single core, you won't see much improvement
at first. But, you likely have multiple cores available to it. In the very last step,
you'll attempt to run your code with multiple cores, which you will hopefully see an
improvement.
Finally, if you haven't already, you will be required to use the INTERFACES provided for
this assignment. In fact, if you use the provided interfaces, it should be very straightforward, and
much more complicated if you try to break the abstractions.
What does our system look like?
The following picture is an overview of the system components:
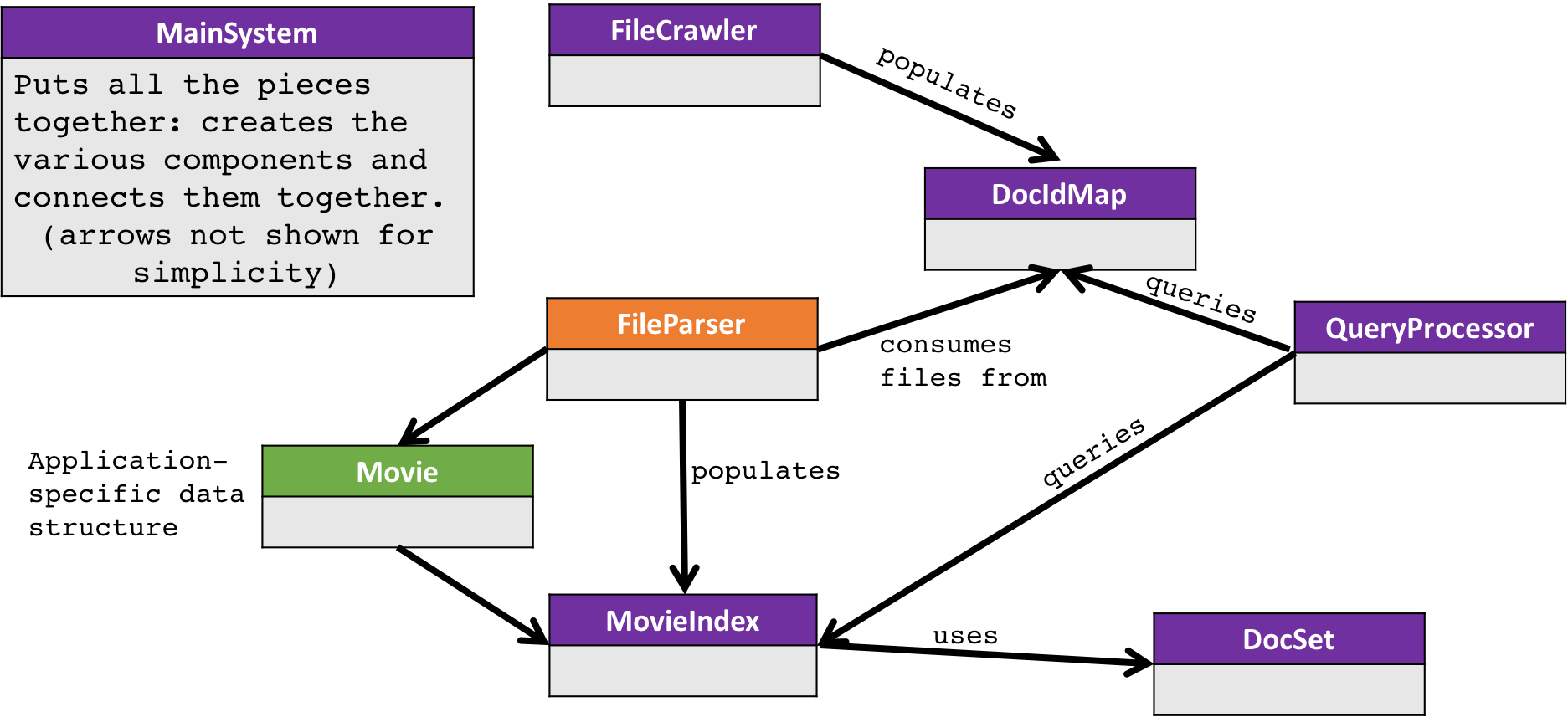
You'll primarily be working with the FileParser (in orange), as well as the MainSystem.
The overall MovieIndex and DocSet look something like this:
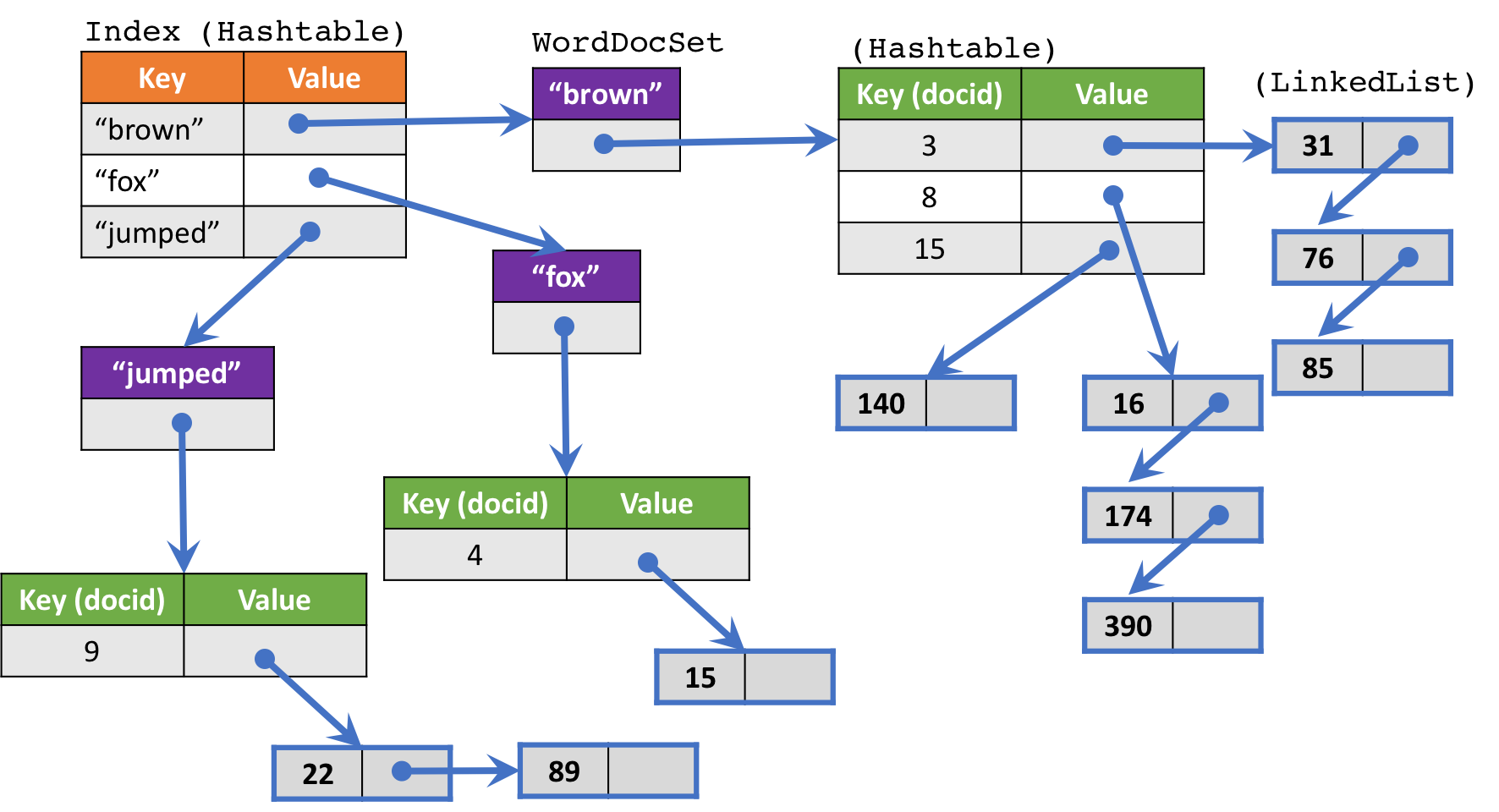
We have a unique DocSet for every unique word in every movie title. The DocSet maintains a list
of DocId's (which document contains the movie with this word) and a list of rows in that document
(which row the specific movie is in).
When we ask the index for a set SearchResults for a given word, a list of docId-rowId pairs is returned.
Then, we use that information to go look up the specific row in the file and return that row to the customer.
This is the overall flow:
- The FileCrawler starts at a given directory and puts all the files in the DocIdMap,
which assigns a unique ID to that file.
- The FileParser gets all the files from the DocIdMap, reads in each row (to an
application-specific data structure call a movie) and gives that to the MovieIndex.
- The MovieIndex chooses how to index the Movie datastructure, storing the information
using the DocSet.
- When all the files have been indexed, the QueryProcessor gets a request from a customer
(e.g. "Give me all movies with SISTER in the title"), asks the MovieIndex for the
relevant records, and returns them to the customer.
Step 1: Write the FileParser
Download the code for this assignment. Spend some time familiarizing yourself, specifically with
the header files that describe the interface to the provided system.
The most relevant files:
- fileparser.c
- fileparser.h
- docidmap.h
- movie.h
- movieIndex.h
- main.c
Then, open the FileParser code and implement the specified pieces. Specifically, what you'll be
doing is going through all the files that have been crawled (that is, identified and put
in the docId map), parse them, and pass them to the movieIndex to be indexed.
Run the tests and your code, making sure you're satisfied with it.
Finishing Step 1
When you're done with this step:
- Commit your code! And push it to github, if you haven't done this yet.
- Tag your code with "A4-part1"
- Run your code on the provided "movies-huge" directory. This will take a while.
- Take note of how long the indexer reported to take indexing the files.
(both time and number of files). You'll need to report this for your final submission,
so don't forget it!
An example invocation:
adrienne@virtualbox$ ./main data_small/
Crawling directory tree starting at: data_small/
Crawled 24 files.
Parsing and indexing files...
Took 432313 microseconds to parse 24 files.
22197 entries in the index.
Enter a term to search for, or q to quit: seattle
Getting docs for movieset term: "seattle"
tt3277988|tvEpisode|Seattle|Seattle|0|2013|\N|42|Reality-TV (data_small/xcm, row 878)
tt3281696|tvEpisode|Denver Broncos vs. Seattle Seahawks|Denver Broncos vs. Seattle Seahawks|0|1997|\N|\N|Sport (data_small/xco, row 418)
tt3281716|tvEpisode|Seattle Seahawks vs. Dallas Cowboys|Seattle Seahawks vs. Dallas Cowboys|0|1980|\N|\N|Sport (data_small/xco, row 427)
tt3281748|tvEpisode|Seattle Seahawks vs. Los Angeles Raiders|Seattle Seahawks vs. Los Angeles Raiders|0|1992|\N|\N|Sport (data_small/xco, row 440)
tt3211900|tvEpisode|Wasted in Seattle|Wasted in Seattle|0|2013|\N|44|Crime,Documentary (data_small/xbj, row 927)
tt3245458|tvEpisode|Seattle Seahawks: Road to 2008|Seattle Seahawks: Road to 2008|0|2008|\N|23|\N (data_small/xby, row 532)
tt3247806|tvEpisode|St. Louis Cardinals vs. Seattle Seahawks|St. Louis Cardinals vs. Seattle Seahawks|0|1976|\N|\N|Sport (data_small/xbz, row 561)
Enter a term to search for, or q to quit:
Step 2: Build a multithreaded indexer
Now that we have an indexer, we're going to multi-thread the FileParser.
Changes to make:
- In fileparser.c, fill in the methods
ParseTheFiles_MT
and IndexTheFile_MT.
- When
ParseTheFiles_MT is called, it should create 5
new threads to run the function IndexTheFile_MT.
- In IndexTheFile_MT, the threads will be sharing access to the iterator providing
filenames, and access to the index. You'll have to prevent the threads from
colliding access by using a mutex (in the readings: Mutexes).
Finishing Step 2
When you're done with this step:
- Commit your code! And push it to github, if you haven't done this yet.
- Tag your code with "A4-part2"
- Run your code on the provided "movies-huge" directory. This will take a while.
- I don't want to put the huge files in git; follow the directions below to get them.
- Navigate to your A4 directory in virtual box.
- Run the commands:
aha@VirtualBox:~/cs5007/adrienne/A4$ wget https://course.ccs.neu.edu/cs5007su18-seattle/resources/movie_data.tar.gz
aha@VirtualBox:~/cs5007/adrienne/A4$ tar -xvzf movie_data.tar.gz
You should find a data directory with a bunch of files.
- There's a chance you'll run out of memory with the huge directory.
If you do, delete some of the files and try again. When you submit your
notes on Blackboard, make a note of how many files you could manage.
- Take note of how long the indexer reported to take indexing the files.
(both time and number of files). You'll need to report this for your final submission,
so don't forget it!
Experiment
Now that your program works, let's do some experimentation. We spoke in class about how
a computer with a single processor won't have much benefit when using multiple threads.
We can measure the difference though.
Further, since we're running a virtual machine, we can tell it how many cores to use.
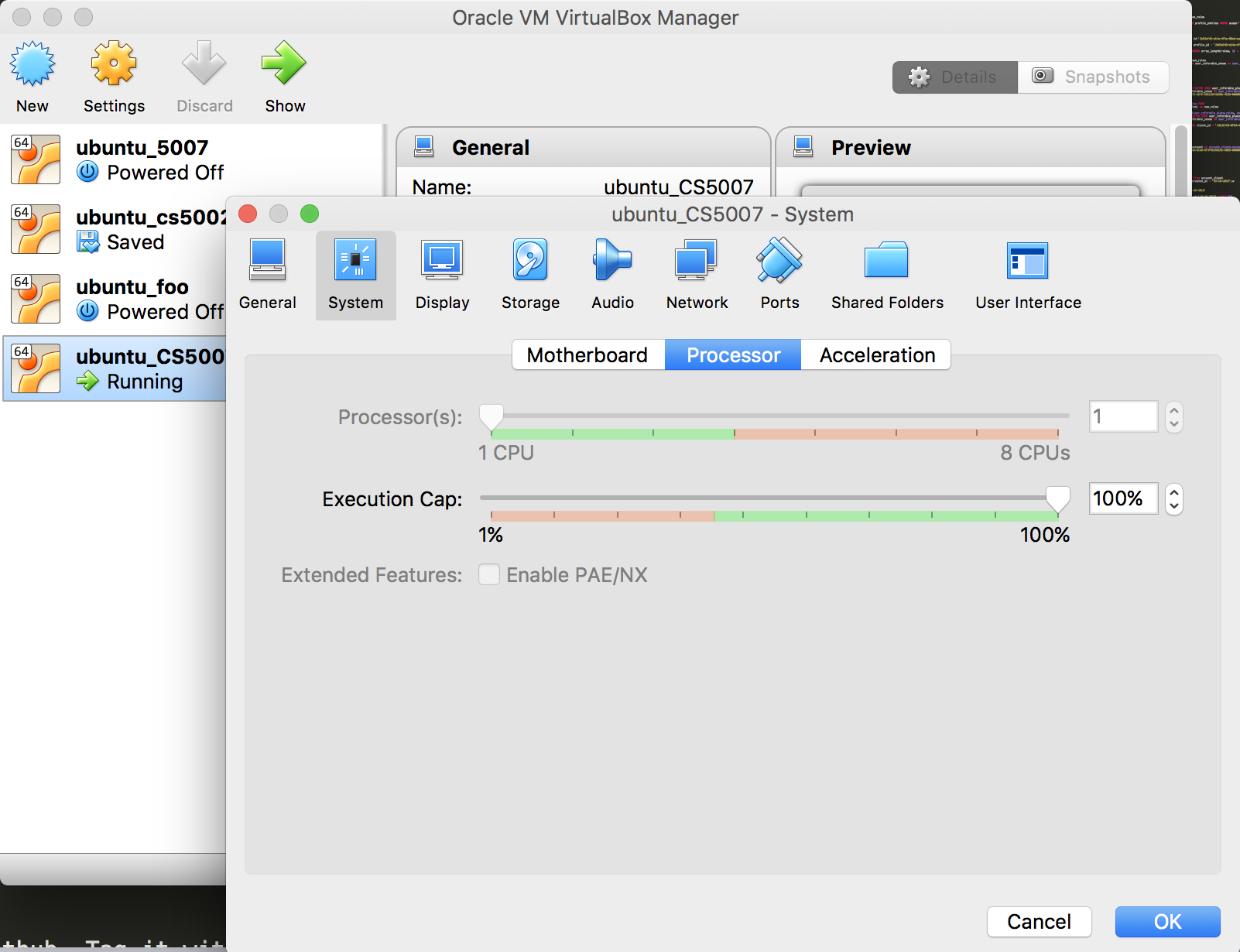
If your machine has multiple cores, it will show on this screen. Crank up the cores, see how
performance improves!
Submission
Submit your assignment by pushing your code to Github. Tag it with the tag a4-final.
Tag your last commit, and submit the tag on Blackboard by the due date, midnight (Pacific Time).
In addition, include your notes on how long it takes to parse the files (for both a single thread and multithreaded), and if there is a difference
if you were able to increase the number of cores.
- Please submit something by the duedate even if you know it's not complete.
- No submission means no re-submit: it's just a 0.
- Please make sure your submission compiles, even if you need to comment out code that isn't compiling.