- graph-based methods usually require a way to check whether a given graph edge intersects with a given obstacle
- Real Time Rendering by Moller et al is a good reference for intersection test algorithms (which are also important in graphics)
- one common case is checking the intersection of a planar line segment with an axis-aligned planar rectangle
- we can leverage the separating axis theorem: two polygons are disjoint iff their projections onto some line through the origin (the “separating axis”) are disjoint
- further, if two polygons are disjoint, there will be a separating axis perpendicular to a face of one of them
- thus it suffices to check axes parallel to all face normals; if the projections of the two polygons are not disjoint on any of them, then the polygons are not disjoint, and vice-versa
- when one polygon is an AA Rect and the other a line segment, we have to check only three axes:
- an axis parallel to
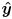 , which is the normal of the top and bottom faces of the rect
, which is the normal of the top and bottom faces of the rect - an axis parallel to
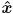 , which is the normal of the left and right faces of the rect
, which is the normal of the left and right faces of the rect - an axis perpendicular to the line segment
- an axis parallel to
- it is easiest to formulate this if we represent
- the rect as its center point
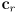 plus a vector
plus a vector 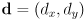 from to its upper right corner (
from to its upper right corner (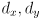 are half the width and half the height of the rect)
are half the width and half the height of the rect) - the line segment as its center point
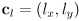 plus a vector
plus a vector 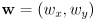 from
from 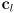 to one of its end points (i.e. the two endpoints are
to one of its end points (i.e. the two endpoints are 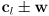 )
)
- the rect as its center point
- first translate both the rect and the segment by
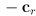 , so the rect is centered at the origin
, so the rect is centered at the origin- i.e. set
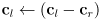 and
and 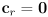
- i.e. set
- then the projection of the rect onto the
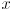 axis is symmetric about the origin, and extends
axis is symmetric about the origin, and extends 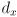 out from the origin
out from the origin - the projection of the segment onto the axis is
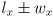 ; the closest this comes to the origin is
; the closest this comes to the origin is 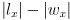
- the projections will be disjoint iff
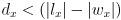 (1)
(1) - the
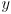 axis check is similar:
axis check is similar: 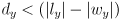 (2)
(2) - now rotate
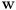 by
by 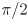 to get a vector
to get a vector 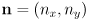 perpendicular to the segment; this boils down to
perpendicular to the segment; this boils down to 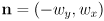
- the projection of the rect onto the axis with direction
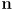 is also symmetric about the origin, and extends out at most
is also symmetric about the origin, and extends out at most 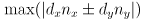
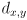 are always positive, but
are always positive, but 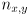 each be positive or negative; reasoning about the four possible sign combinations shows that
each be positive or negative; reasoning about the four possible sign combinations shows that
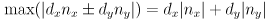
- the projection of the segment onto is (
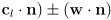
- the closest this comes to the origin is
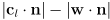
- thus, the projections will be disjoint iff
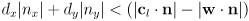 ; writing out the dot products gives
; writing out the dot products gives
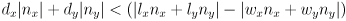 (3)
(3) - the rect and the segment are disjoint iff any of (1–3) is true; otherwise they intersect
- change the
 comparisons to
comparisons to 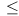 to allow segments which are merely tangent to the rect to be considered as not intersecting (important in visibility graph approaches where most segment endpoints are actually on obstacle vertices)
to allow segments which are merely tangent to the rect to be considered as not intersecting (important in visibility graph approaches where most segment endpoints are actually on obstacle vertices) - this matlab script demonstrates the approach
- we will use the notation
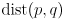 to return the distance (edge weight) from vertex
to return the distance (edge weight) from vertex 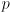 to
to 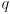
- we will also say that, once a vertex
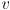 is “solved”, that
is “solved”, that 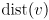 is the length of a shortest path from to
is the length of a shortest path from to 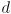
- given a destination vertex , the algorithm will find a shortest path from every other vertex
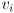 to , and it will also find the path lengths
to , and it will also find the path lengths 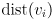
- invariant: for any vertex already in T, a shortest path from to follows the tree edges, and is the sum of the edge lengths along that path
- the tree is grown one vertex at a time by selecting a new vertex
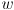 reachable in one step from some vertex in T such that
reachable in one step from some vertex in T such that 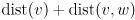 is minimal; i.e. is the closest known “unsolved” vertex reachable in one step from a “solved” vertex
is minimal; i.e. is the closest known “unsolved” vertex reachable in one step from a “solved” vertex - it is easy to see that this is correct: if there were a shorter path from to by first going through some other vertex
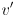 then
then- if were in T we would have picked it instead of
- if were not in T then we would have picked it instead of
- if
- the parent of in the spanning tree T is , and
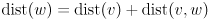
the heap-based algorithm could be implemented like this:
init empty heap H of vertices sorted by dist
for each vertex v set v.visited = false, v.dist = infinity
set goal.dist = 0, goal.visited = true
add all vertices to H # O(N) amortized with Fibonacci heap
while H not empty
v = extract-min H # O(log N) amortized with Fibonacci heap
set v.visited = true
for each neighbor vertex n of v with n.visited = false and n.dist > (v.dist + dist(v,n))
set n.next = v, n.dist = v.dist + dist(v,n)
decrease-key of n in H # O(1) amortized with Fibonacci heap
decrease-key operationdecrease-key actually often perform better in practice.Here is one way to modify the above algorithm so that it does not require decrease-key, and so that it does not mutate the sort key of any object that has already been added to the priority queue:
init empty priority queue Q of (vertex, dist) pairs sorted by dist
for each vertex v set v.visited = false, v.dist = infinity
set goal.dist = 0
add (goal, 0) to Q # O(log n) with binary heap (and Java PriorityQueue)
while Q not empty
(v, d) = pop Q # O(log n) with binary heap (and Java PriorityQueue)
if not v.visited
set v.visited = true
for each neighbor vertex n of v with n.visited = false and n.dist > (v.dist + dist(v,n))
set n.next = v, n.dist = v.dist + dist(v,n)
add (n, n.dist) to Q # O(log n) with binary heap (and Java PriorityQueue)
The asymptotic running time increases to ![]() in this implementation.
in this implementation.
