Examplar
Motivation
In a typical homework scenario, students would write their implementation, and
write test cases to demonstrate that it works. The implementations would be
checked against instructor-written tests —
Any design effort, no matter what discipline, requires both understanding the requirements of the problem domain and then subsequently implementing those requirements correctly. Instructor-written tests only check whether the student implementation is correct, but do not provide an automated way to check whether the student’s understanding of the requirements is correct.
Remember: even if both of them are encoded as checkExpect calls inside testSomething methods, examples build intuition and understanding about a problem; test cases build confidence that an implementation matches its requirements.
Each of the chaffs in this course will have one plausible bug in them; they will not contain multiple mistakes. The chaffs are designed to highlight common misconceptions about the designs you are working on; they’re not designed to be cryptic. (There are no chaffs that can only be triggered by guessing some intricate Konami cheat code!)
Once you’ve developed a suite of examples, it should then take minimal effort for you to reuse those examples to guide your own implementation as you develop it. As we explain below, you’ll be able to use your Examplar work completely unchanged. (Note that your implementation still deserves many more tests than the examples you submit for Examplar! Nevertheless the examples will give you a solid start.)
Mechanics
We will provide you with an interface for you to code against, and a stub implementation of that interface. The stub will simply throw exceptions in all of its methods; it does not have any interesting behavior of its own. It is only there to ensure that your code compiles successfully.
You will write your examples as follows:
// This import stays standard import tester.Tester; // This package name will be given to you in the starter code import the.provided.library.*; class ExamplarTestsClassName { // class name will be specified by the assignment boolean testYourScenarioHere(Tester t) { IFoo foo = new FooImplementation(...); return t.checkExpect(...); } ... }
When Examplar runs, it will replace the stub implementation with each of the wheats and chaffs in turn, and run your test methods against each such implementation.
When you submit your work, submit only your
ExamplarTestsClassName.java file —
Once you’ve finished an Examplar assignment, your examples can be used completely unchanged to then test your own implementation: you’ll simply remove the import the.provided.library.* line at the top, so that you’re testing your own code instead of the stubs. This helps ensure that before you’ve spent any time trying to test incorrect code, you already have a good baseline of correct examples that can definitely help catch incorrect code.
Grading
An Examplar submission will be evaluated on four criteria:
Correctness: how many of the wheats do not fail in any of your test methods? Ideally, no wheats should cause any of your examples to fail —
after all, the wheats define what “correct” behavior is, so if your examples fail on a wheat, then your examples misunderstand the behavior that they’re demonstrating. Thoroughness: how many of the chaffs cause at least one of your test methods to fail? Ideally, all chaffs should cause some of your examples to fail —
otherwise, your examples aren’t checking for enough interesting behaviors. Precision: for each chaff, is there a distinct subset of examples that fail on that chaff? Think of it like a guessing game: if I’m thinking of something, and you guess that it is blue, and that it is big —
is that precise enough to distinguish between “the sky” and “the ocean”? (Or just a very big, broken billboard...) Ideally, every chaff should be caught by a unique subset of your test methods. Usefulness: for each test method, did that test method catch a unique subset of chaffs? In other words, are any of the test methods redudnant, such that they catch exactly the same chaffs as some other test method? It’s entirely possible that while you are developing your examples, you try out several that turn out to be redundant or uninformative. You should eliminate those unhelpful examples. Ideally, your suite of test methods should be as small as possible, so that everything that remains is a useful example that helps you diagnose bugs in your later implementations..
{kind=link}
The phrasing of the options above might seem a bit weird. Why say “how many wheats do not cause any test methods to fail,” rather than “how many wheats pass all the examples”? Likewise, why do we say that chaffs should each “cause at least one of the test methods to fail”? Put simply: because not every test method tests every behavior simultaneously. In an object-oriented setting, when you are testing an interface with multiple methods, it’s entirely possible that a chaff might have a bug in one method, while some test might happen to only call a different method. In that scenario, it’s not accurate to say that your test “passed” or “failed” – it’s just not relevant to that chaff.
(In the extreme case, consider the following two lousy tests:
boolean testThatAcceptsEverything(Tester t) { return t.checkExpect(true, true); } boolean testThatRejectsEverything(Tester t) { return t.checkExpect(true, false); }
These criteria are definitely in tension with one another: usefulness wants you to write as few test methods as possible; precision wants you to write enough test methods to distinguish among all the chaffs. Correctness is trivial if you write no tests; thoroughness is trivial if you reject everything. Balancing these four requirements takes some practice!
Correctness and thoroughness are the most important attributes we will focus on this semester. Accordingly, they will each be worth 40% of the grade for an Examplar submission. Precision and uniqueness are trickier to get right, so they will each be worth 10% of the grade for an Examplar submission. (On every assignment we give you, it will be possible to get 100% on all four attributes, but you may decide that it is not worth your time to hunt down the last few bits of uniqueness or precision.)
What Examplar grading looks like
Our implementation of Examplar is integrated into Handins, and there will be dedicated homeworks for Examplar submissions. When you look at the grading feedback on Examplar submissions, each of the wheats and chaffs will be anonymized: Wheat #0, Chaff #12, etc. The numbers are stable: e.g., if you submit multiple times, then Chaff #12 will be the same chaff in every submission.
The feedback you see on Handins will consist of five boxes. The first four boxes correspond to the grading criteria above. They are color-coded: red means no credit on that criterion; yellow means partial credit; and green means full credit. Within each box, you’ll see a “progress bar” indicating how much partial credit you earned.
The grading box for Correctness will show you the (anonymized) names of the
wheats, and which of your test methods (if any) rejected them. Your goal is to
reject none of them:

The Thoroughness, Precision and Usefulness boxes will not show you any names; they’ll just show you the score you earned. All three of them rely on the same underlying data, which will be shown below.



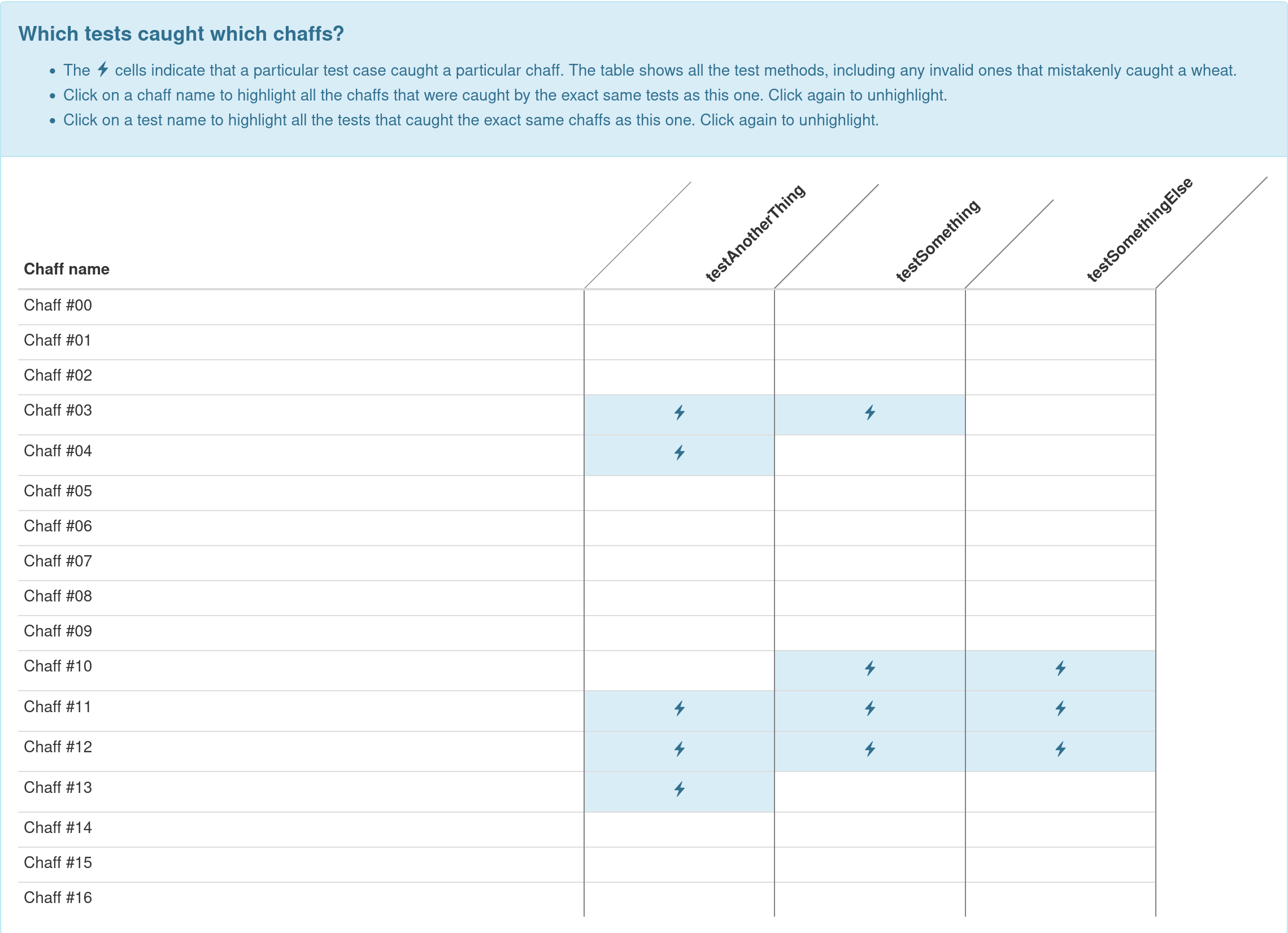
After the four grading boxes, you’ll see a test matrix box in blue. The rows of this box correspond to each of our chaffs, and the columns correspond to each of your test methods. A marked cell indicates that a particular test method failed on a particular chaff.
The Thoroughness score counts how many rows are non-empty (that is, rows for which at least one test method caught that chaff). In this example, there are only six non-empty rows, so the Thoroughness score is 6 out of 17.
The Precision score counts how many rows are unique (that is, have a unique set of marked columns in them). In this example, there are five distinct rows (empty; column 1 marked; columns 1 and 2 marked; columns 2 and 3 marked; all columns marked), so the Precision score is 5 out of 17.
The Usefulness score counts how many columns are unique (that is, have a unique set of marked rows in them). In this example, all three columns are distinct, so the Usefulness score is 3 out of 3.
When there are lots of chaffs and lots of test methods, it can be tricky to
immediately see which ones are unique or not. To help with this, the table is
interactive: you can click on a row (or column) name to highlight all rows (or
columns) with the same markings as that one.
Hints for writing good Examplar examples
First focus on making all your test methods Correct.
When in doubt, try it out. If you are unsure what a particular behavior should be, come up with a hypothesis of what it should be, then create an example that triggers that behavior, and measure whether the output matches your hypothesis. Examplar will show you whether your example is Correct or not.
Once your tests are Correct, work on improving Thoroughness (without sacrificing Correctness).
Only once you’ve gotten everything Correct and Thorough, should you spend time trying to improve Precision and Usefulness.
Read through the purpose statements for each method. Think about ways to (ab)use or misunderstand each of the parameters of the method —
perhaps the edge cases are off by one, or the arguments are not in the expected order, or similar. Construct an example such that if the parameters are used correctly then the test passes, but if they are used incorrectly then the test fails. You may well not want to use checkExpects to check the entirety of your value – such checks might be too precise to capture the behavior of all the wheats. For example, if the specification allows multiple possible correct answers, then using checkExpect to check for one specific correct answer might well cause some of the wheats to fail your examples.
Similarly, you might want to only check a summary or a computed property of the output. For instance, if you are checking that filtering a set removes the correct elements, you might construct a set with a known quantity of wanted and unwanted elements, and then check that the size of the set after filtering is correct: that may be enough to catch several simple bugs, without overly rigidly specifying the exact order of the set’s elements.
Your examples should probably be pretty short. Most of the bugs in the chaffs can be found with fairly minimal effort, meaning only a few method calls (or a predictable sequence of method calls) should be needed.
Document for yourself (in the form of comments) what assumptions you’re making about which parts of the underlying implementation must be correct, or at least mutually consistent, in order for your test to make sense. It’s pointless to assume that everything about a chaff is broken, because there would not be anything you could rely upon to measure its behavior. In this course, all of the chaffs we give you will have a single, plausible bug in them, rather than some mysterious combination of bugs.
To improve precision, look at the test methods that seem to be catching the same chaffs. Brainstorm at least two possible distinct implementation ideas that nevertheless do the same thing on your eaxmples. Ask yourself, “supposing the chaff 1 is doing things this way, and chaff 2 is doing things that way, are there any observations I could make to distinguish them?” (This may be the trickiest part of black-box testing, since you have to guess what the unseen implementation might be doing.)